

On my blog, I’ve often shared my experiences and discoveries in computer vision, particularly the thrilling challenge of teaching a machine to see what it’s never seen before.
But as my journey has evolved, I’ve come to believe that the true, transformative power of this approach lies not just in visual data, but in the intricate, messy, and fascinating world of natural language.
This is my story of a paradigm shift—a deep dive into how I moved from the frustration of endless data labeling to building agile, powerful language models that can understand the unseen.
My first encounter with ZSL in NLP came from a familiar pain point. I was consulting for a start-up that needed to classify incoming customer support tickets. Their product line was in constant flux, with new features and services launching every few months.
This meant our initial text classification model, painstakingly trained on thousands of labeled examples, became obsolete almost overnight. The moment a new product launched, the model’s performance plummeted.
We were trapped in a continuous, resource-intensive cycle of manual data collection, annotation, and retraining. It was an exercise in futility, a data bottleneck that threatened to cripple our progress. I knew there had to be a better way, a more intelligent way, to solve this problem. I needed a system that could learn as fast as the business was changing.
This is where ZSL offered a lifeline. It was about giving it a new way to understand. Instead of building a model to recognize specific phrases tied to a “product return” category, I needed it to understand the concept of a “product return.” I had to move from teaching a model a list of names to giving it a conceptual roadmap of the world.
The Conceptual Roadmap: A New Way to Think
The magic of ZSL in NLP is that it doesn’t need to see a single example of a new class. It simply needs a descriptive phrase. A traditional model might have a hard-coded mental “file folder” for a “Product Inquiry.”
A ZSL model, in contrast, learns to create a mental “fingerprint” for what “Product Inquiry” means. When a new email comes in, it generates a fingerprint for that text and then simply finds the closest conceptual match among all the available category fingerprints.
My initial foray into this world involved building this “conceptual roadmap.” I started with a large, pre-trained language model. Its foundational training had already given it a powerful, internal understanding of language. It knew that “apple” was conceptually related to “fruit” and “orchard” but was far removed from “car.”
My job was to leverage this existing knowledge. I worked with the customer support team to translate their new ticket categories into concise, descriptive phrases. For example, a new category might be “Feedback on Service,” and its description would be something like, “messages containing praise, critique, or suggestions about our customer support team.”
This approach felt incredibly liberating. The model wasn’t memorizing a list of keywords or patterns; it was reasoning about the meaning of the words themselves. An email saying “the chat agent was incredibly helpful and solved my problem in minutes” would get a very high conceptual similarity score to my “Feedback on Service” description, even if the model had never been shown a positive review before.
This semantic understanding allowed the model to immediately start classifying tickets for new products and services the moment they launched. For me, this was a breathtaking shift from being a data janitor to being a conceptual architect. I was no longer feeding the machine; I was teaching it how to think.
Project One: Zero-Shot Text Classification at Scale
My first major project was applying this principle to an archival challenge for a media company. They had a massive, un-catalogued database of news articles spanning years.
Only a small fraction was labeled, and they wanted to organize the entire collection into a new, complex taxonomy of topics that would change over time. Manually labeling millions of articles was a non-starter. This was the perfect crucible for ZSL.
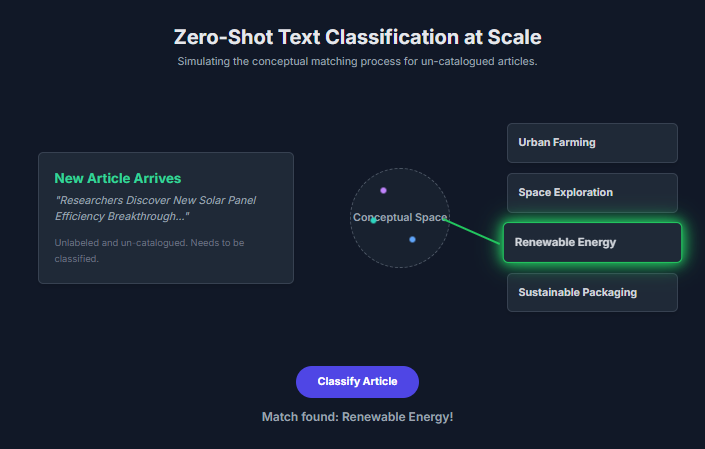
My strategy was simple in its execution but profound in its implication. I used a large language model to create a “conceptual fingerprint” for each article. I then did the same for the editorial team’s new categories, such as “Renewable Energy,” “Urban Farming,” and “Space Exploration.”
A new article about a breakthrough in solar panel efficiency was processed by my model, and its conceptual fingerprint immediately showed a high degree of similarity to the “Renewable Energy” category. It was an instant, high-confidence match.
I still remember the feeling of watching this system work. We could add a new category like “Sustainable Packaging” on a Tuesday morning with a simple description, and by the afternoon, the model had already correctly classified thousands of relevant articles from the entire archive. The system was infinitely scalable and adaptable.
It was not bound by the limitations of its training data; it was empowered by the breadth of its linguistic knowledge. The success of this project fundamentally changed how the company viewed its data and proved to me that ZSL was not just a theoretical concept but a powerful, real-world solution to a critical business problem.
Here is the screenshot of the working of my project on Zero-Shot Text Classification at Scale:
Project Two: Capturing Nuance with Zero-Shot Sentiment Analysis
Buoyed by my success with text classification, I moved on to a more nuanced challenge: sentiment analysis. My next project involved analyzing real-time feedback from a fast-growing mobile game community. Traditional sentiment models were failing spectacularly.
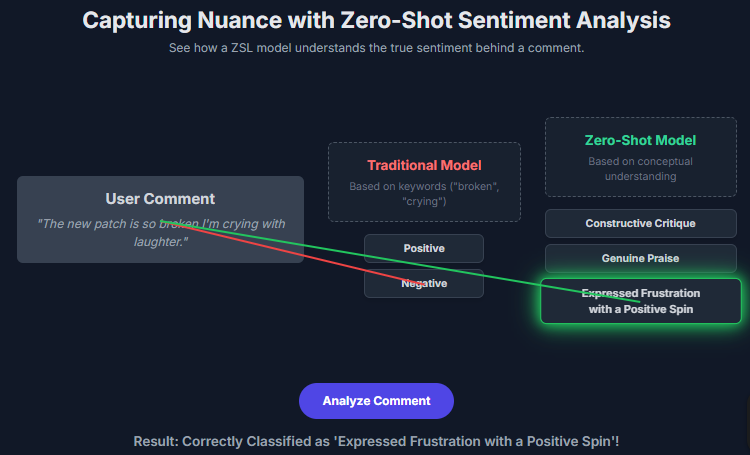
Users weren’t just saying “I hate this game.” They were using rich, ironic language and in-jokes. A comment like, “The new patch is so broken I’m crying with laughter,” would be incorrectly flagged as negative by a standard model. It was a perfect storm of evolving language and cultural context that a model trained on general data simply couldn’t handle.
The Zero-Shot approach offered a path forward. I abandoned the simple “positive/negative/neutral” labels. Instead, I worked with the community managers to define the sentiment categories with descriptive phrases that captured the true emotional state.
My model’s new categories were things like “Expressed Frustration with a Positive Spin,” “Genuine Praise,” and “Constructive Critique.” This felt more authentic and aligned with how humans truly communicate.
I fed the community comments into my ZSL model along with these new, nuanced descriptions. The model’s semantic understanding allowed it to correctly interpret the comment about “crying with laughter.” It saw the positive intent in the word “laughter” and the contextual nuance that overrode the typical negative association with “crying.”
It correctly classified the comment as “Expressed Frustration with a Positive Spin.” This gave us unprecedented insight into user feedback, allowing us to not only understand their feelings but also the underlying reasons for them.
This project taught me that ZSL’s power isn’t just in its ability to handle new categories, but in its capacity to understand the complex, ever-shifting nuances of human language. It empowered our team to move beyond superficial keywords to true comprehension.
Here is the screenshot of my models output:
Project Three: Discovering the Unseen in Highly Specialized Text
My final and most challenging project to date was a testament to ZSL’s precision. I was working with a legal tech firm on a system for Named-Entity Recognition (NER).
Traditional NER models can identify people, places, and organizations, but this firm needed to extract highly specific, domain-specific entities from complex legal documents, such as “Securities Options,” “Patent Claim Numbers,” and “Derivative Contracts.”
These terms were entirely new and niche, and the manual effort required to label a sufficient dataset was simply prohibitive.
I knew my zero-shot approach could work here, but it would require an even more precise touch. The challenge was not just to classify a document, but to pinpoint and label a specific phrase.
My solution was to define these new entities using a highly specific, rule-based description. For example, a “Patent Claim Number” was described as “a specific, alphanumeric code associated with a legal claim within a patent document.”
When the model processed a patent, it would read the entire text and identify any phrase that had a conceptual fingerprint similar to this description. It would then extract that specific phrase and label it.
The results were astonishing. My model, which had never seen a “Warrant to Purchase Common Stock” in a labeled training set, was able to correctly identify it as a “Financial Instrument” because its conceptual understanding of financial language was robust. It could generalize from concepts it knew to identify a precise new phrase.
This proved to me that ZSL’s power extends beyond broad classification and into the realm of highly granular, specialized information extraction. It was the ultimate demonstration of its ability to enable information retrieval in domains where data is sparse and the terminology is constantly evolving.
Here is the screenshot of my working project:

The Journey Continues
My journey with Zero-Shot Learning has been a brilliant experience that has fundamentally reshaped my approach to building AI systems. It represents a paradigm shift away from the brute-force, data-heavy methods of the past and towards a new era of agile, conceptually-driven AI.
The lessons I’ve learned are clear: the most powerful models are not those with the most data, but those that can reason and generalize.
The applications I’ve shared are just the beginning. I believe that ZSL is the key to creating intelligent systems that can adapt in real time to new customer needs, new scientific discoveries, and new cultural shifts. It’s how we move towards building AI that is truly intelligent, not just well-trained. I’m excited to continue this journey, exploring the boundless potential of ZSL and sharing my insights with you.
Explore further into the fascinating world of Zero-Shot Learning by reading my main pillar post: What is Zero-Shot Learning (ZSL) in AI.

Stay ahead of the curve with the latest insights, tips, and trends in AI, technology, and innovation.