

My dear reader, I’ve spent countless hours in the fascinating world of AI, and I have to tell you, the pace of innovation is truly breathtaking. Just when I thought I had a solid grasp on one concept, another one would come along and completely blow my mind.
Today, I want to share a concept that did just that. It’s an idea that I believe is fundamentally changing how we think about artificial intelligence.
I’m talking about Zero Shot Learning (ZSL).
You know how it works with traditional machine learning, right? We have to feed a model thousands of labeled examples to teach it a single concept. If you want an AI to recognize a dog, you need to show it thousands of pictures of dogs. A lot of pictures of cats for a cat.
It’s a massive, resource-intensive effort in data collection, and it’s something I’ve struggled with many times in my own projects. I remember one time, trying to build a classifier for rare bird species. It was a nightmare. Finding enough high-quality, labeled images for a specific type of arctic tern felt almost impossible.
But what if an AI could recognize something it had never seen before? What if I could tell it what a “platypus” is using a simple description, and it would immediately understand and be able to find one in a picture? This, my friends, is the revolutionary promise of Zero-Shot Learning. It’s like giving an AI a dose of common sense, and it’s a topic that I’m so excited to share with you today.
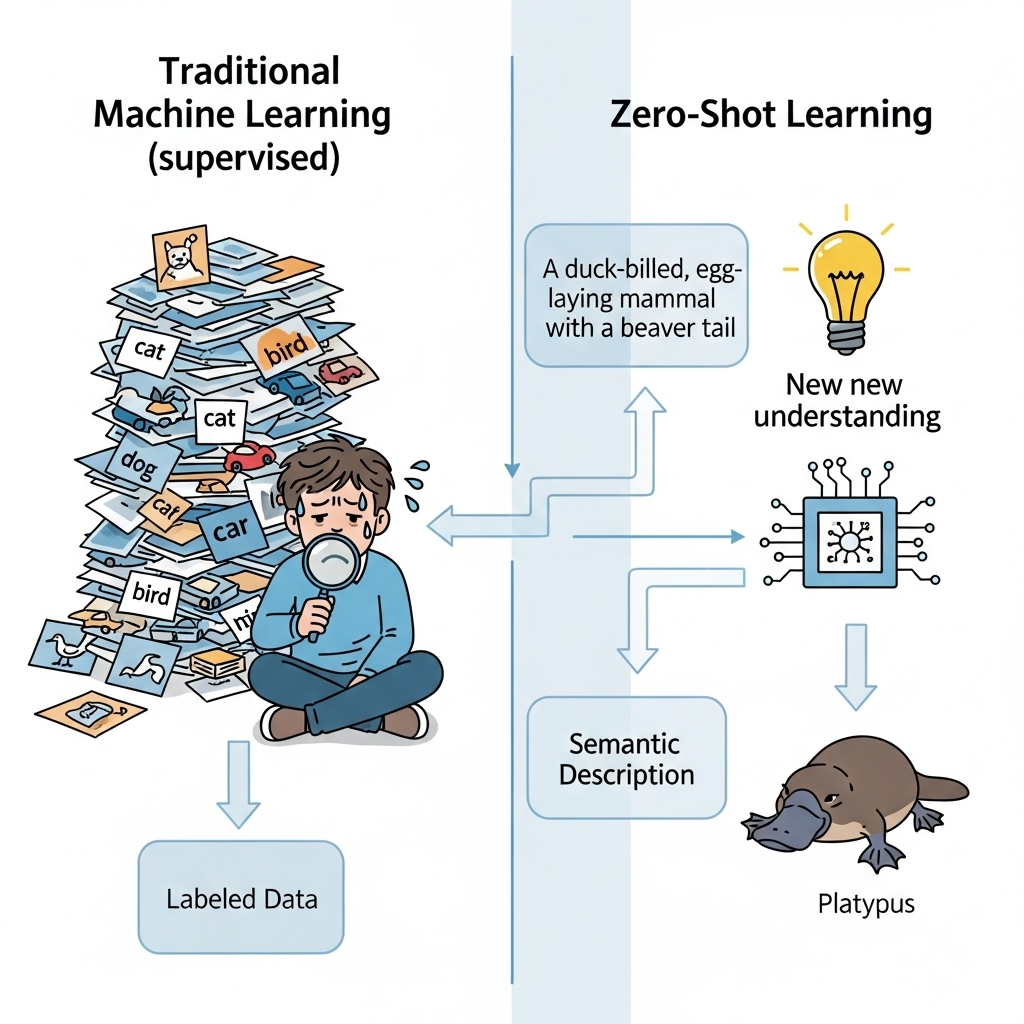
In this guide, I want to take you on a journey to understand how ZSL works. We’ll break down the core components, explore its incredible real-world applications, and even look at how it compares to other concepts like Few-Shot Learning. By the end of this, I hope you’ll be just as excited as I am about this new frontier in AI, and you’ll see why it’s a game-changer for tackling some of the biggest challenges in the field.
What Is Zero Shot Learning?
Zero-shot learning is a machine learning technique that enables a language model to recognize and classify data for categories it has never seen during its training phase.
It works by using a vast amount of previously learned knowledge and then using that knowledge to generalize and make predictions on new, unseen data.
To understand this, consider the analogy of a child learning about animals. A child might learn about dogs, cats, and birds by seeing pictures of them and being told their names.
This is traditional supervised learning. Now, imagine you show the child a picture of a zebra. Even if they have never seen a zebra before, they can likely identify it by using their existing knowledge of other animals.
They might reason that it is “a type of horse with black and white stripes.” This is the core concept of zero-shot learning. The child, or the model in this case, uses a descriptive intermediary representation. In case of Zero shot learning, “horse” and “black and white stripes” are used to classify the new object.
In the context of AI, zero-shot learning models are often trained on large datasets where each data point (e.g., an image) is paired with a rich descriptive text.
The model learns to associate visual features with semantic descriptions. When presented with an unseen category, it doesn’t need to be trained on new examples.
Instead, it classifies the new data by finding the best match between the data’s features and the textual descriptions of the new category. This capability is particularly useful in fields where data for every possible category is difficult or impossible to collect, such as in medical imaging or rare animal species identification.
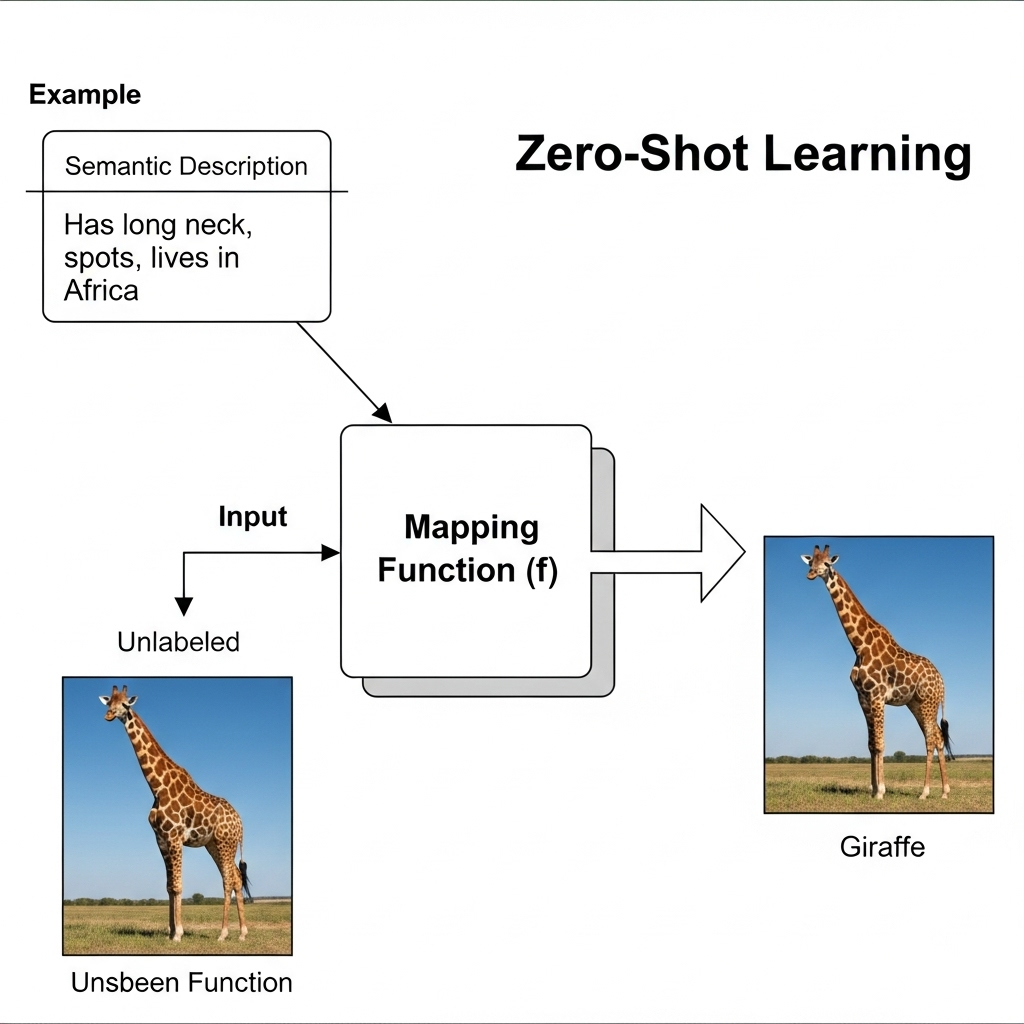
How Zero Shot Learning Works
Zero-shot learning works by creating a bridge between what a model has seen and what it has only read about, enabling it to classify new, unseen data.
This process relies on two critical components: semantic descriptions and a mapping function.
Semantic Descriptions
Semantic descriptions give AI the conceptual understanding of things beyond simple data. Instead of just memorizing pixels for a “cat,” a zero-shot learning model learns that a “cat” is associated with attributes like “feline,” “furry,” and “meows.”
When it encounters a new animal like a “lion,” it can generalize and classify it by mapping its visual features to a new combination of attributes, such as “feline” and “wild.”
These descriptions can take the form of:
- Attribute Vectors: Lists of binary or continuous attributes for a category (e.g., for an ostrich: [has_feathers=1, can_fly=0]).
- Word Embeddings: Numerical vectors that capture the meaning and contextual relationships of a word or phrase. Words with similar meanings are numerically closer in a multi-dimensional “semantic space,” allowing the model to understand analogies and relationships.
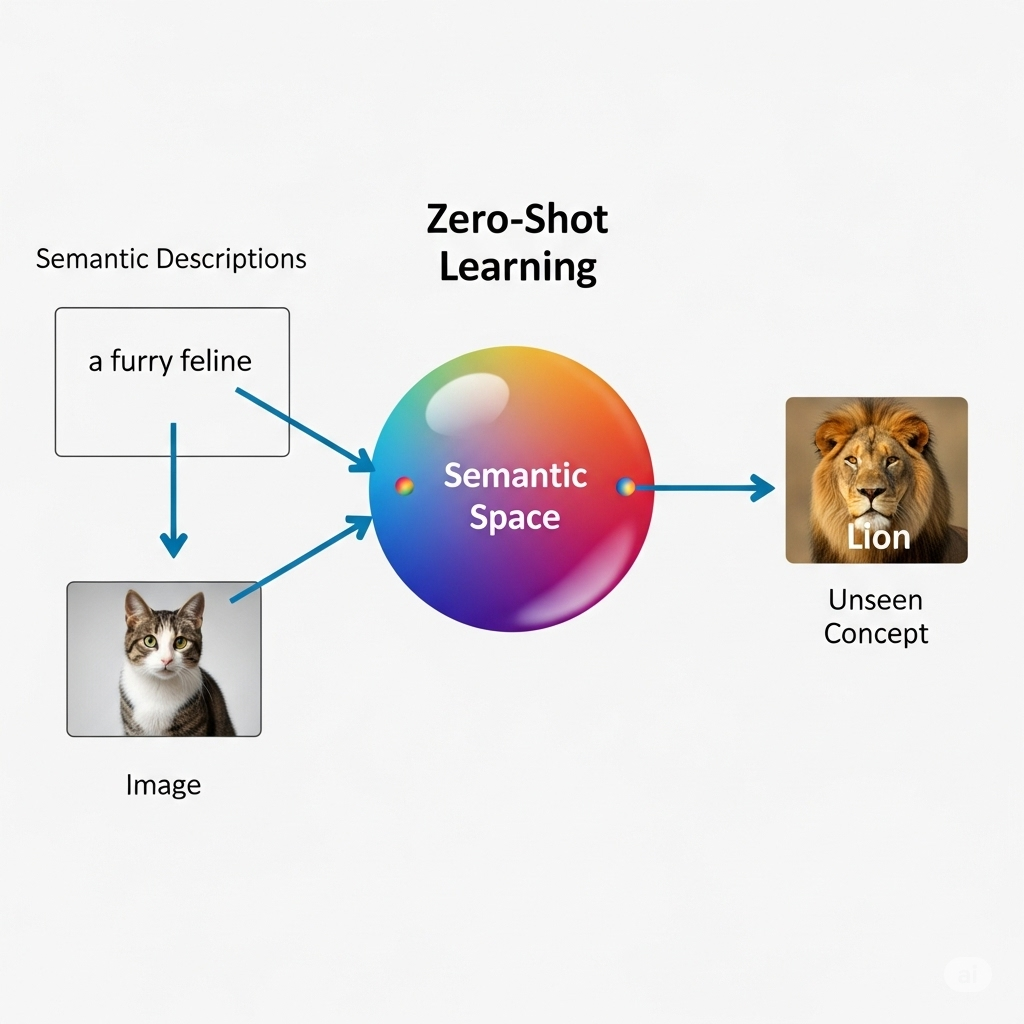
A Mapping Function
The mapping function acts as the AI’s translator, building a precise connection between the raw data (like the pixels of an image) and the semantic descriptions. This function, typically a neural network, is trained to convert information from one representation space into another.
During the training phase, the model learns to map data from known categories to their corresponding semantic descriptions.
For example, it learns to associate images of dogs with the word embedding for “dog.” In the inference phase, when presented with an image of an unseen category (e.g., a zebra), the model uses its learned mapping function to convert the image into a numerical vector in the semantic space.
It then classifies the image by finding the closest match among all the available semantic descriptions, correctly identifying the image as a “zebra” even though it has never seen one before.
How This Translator Learns and Works
When I first started to tackle the problem of zero-shot learning, I realized I had to let go of some of the fundamental assumptions of traditional machine learning. The challenge was to build a system that could reason, a system that could use its existing knowledge to understand something entirely new.
I had to create a bridge between the visual world and the conceptual world, a task that felt more like teaching a child than programming a machine.
This journey led me to a two-phase architecture that, in my experience, is the most robust way to approach ZSL: the training phase, where I build the system’s “conceptual dictionary” and its translator, and the inference phase, where I put that translator to the ultimate test.
My work is founded on two core principles.
- First, every concept, whether it’s a visual image or a word, has to live in a shared, common space of meaning. I call this the semantic space.
- Second, I need a sophisticated function that can reliably take a visual input and map it directly into that semantic space.
This is the mapping function, and its design and training are what make this entire endeavor possible. For me, the true power of zero-Shot Learning lies in this transformation i.e., moving from a model that simply memorizes to one that can generalize and reason.
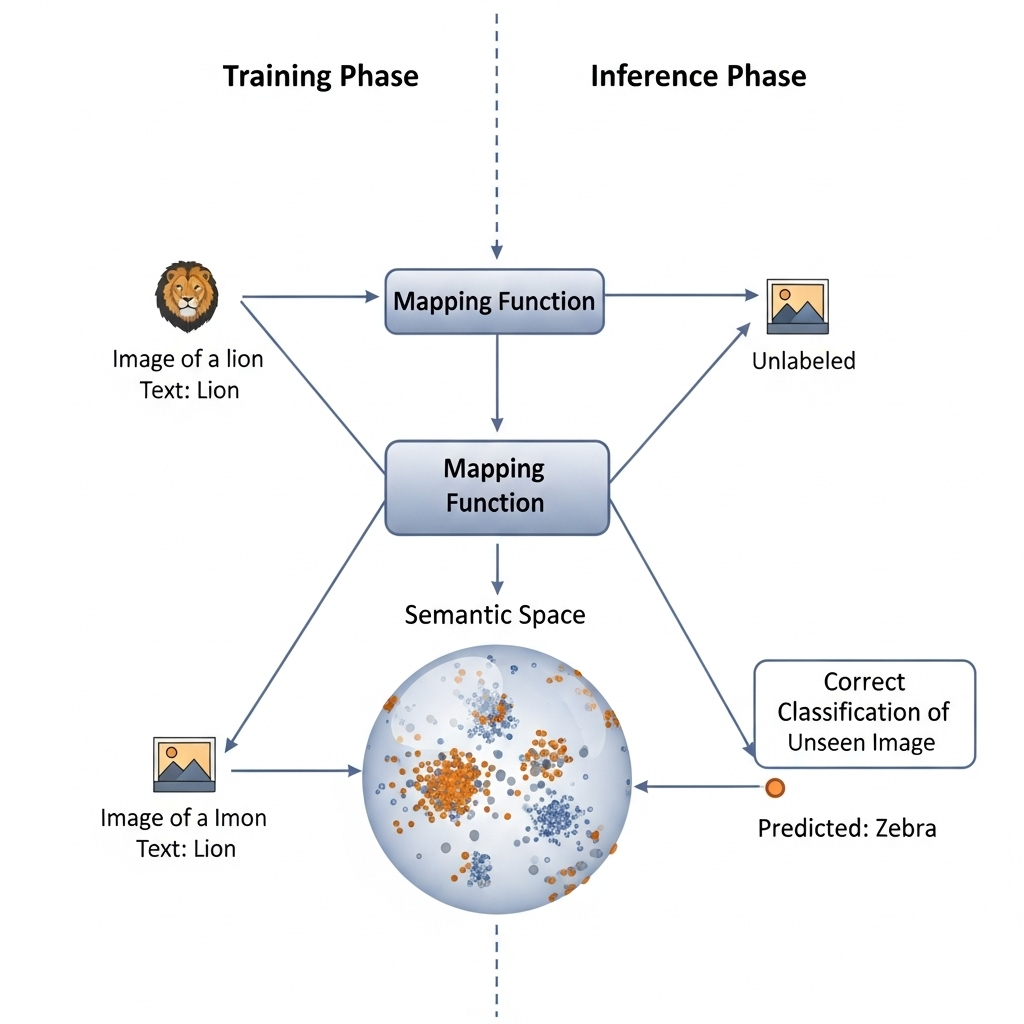
Core Mechanisms & Model Types
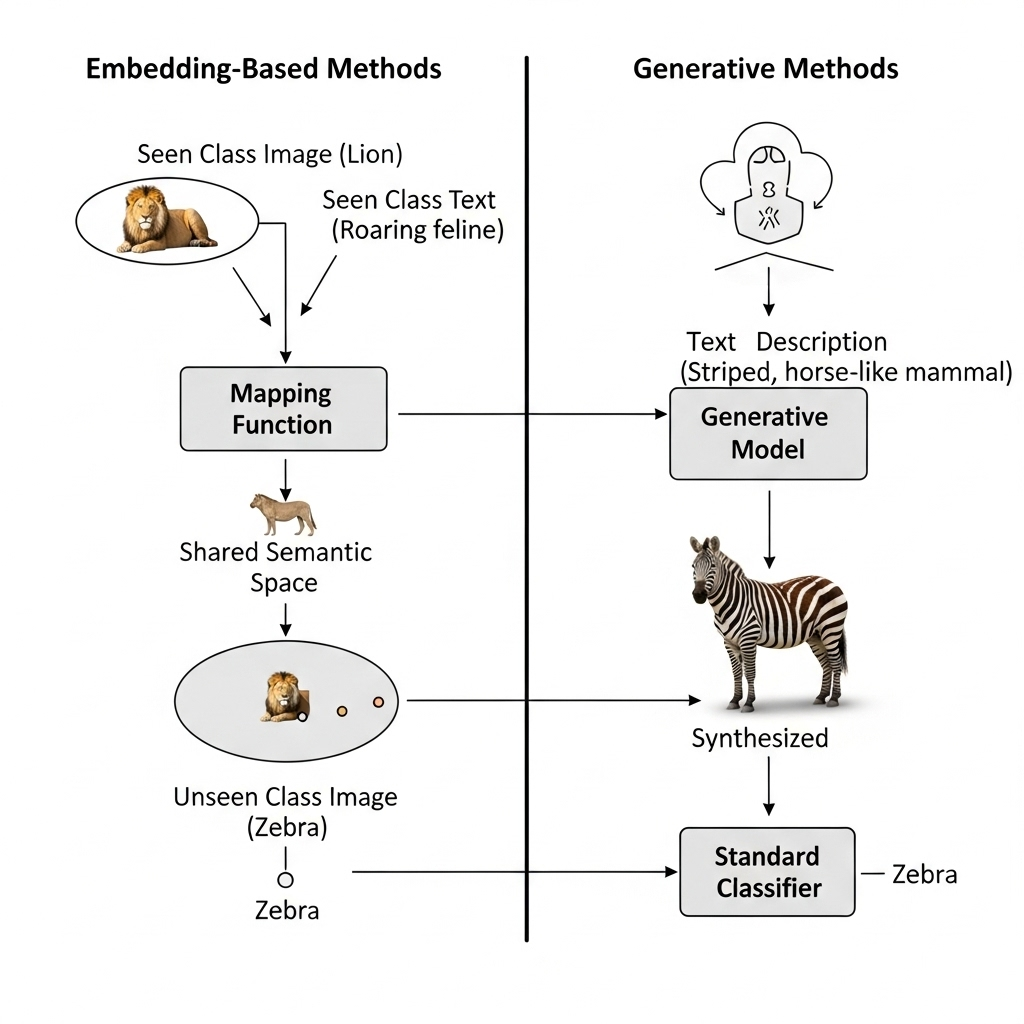
As I dove deeper into zero-shot learning, I realized it’s not just a single technique, but a whole family of approaches built on a fascinating core idea: connecting the visible to the invisible. Basically, ZSL relies on two main types of models: embedding-based methods and generative methods.
Embedding Approaches
The goal here is to learn a function that can project both visual data (like an image of a zebra) and semantic data (like the text “striped, horse-like mamcmal”) into a single, shared embedding space. Think of it as a common language. In this space, objects that are semantically similar are also close together.
I found that the real magic is in the training. The model only learns this shared space using the “seen” classes i.e., images of cats, dogs, birds, etc.
It learns to associate their visual features with their text descriptions. When we show it a zebra, a class it’s never seen before, the model projects the zebra’s visual features into this same space. It then finds the closest semantic description which, because of how the space was designed, turns out to be “striped, horse-like mammal” rather than “carnivorous feline.” It’s an elegant solution.
Generative Methods
After a while, I started exploring a more creative solution: what if the model could just create what it’s missing? That’s the idea behind generative zero-shot learning.
Instead of just trying to find the right description for an unseen class, a generative model uses the semantic description to synthesize what an image of that unseen class would look like.
For example, when given the text description “a striped, horse-like mammal,” a generative model might create a fake visual representation of a zebra. It can then use this generated “fake” image to train a standard classifier. It’s like the model is creating its own training data on the fly.
This approach is powerful because it addresses some of the challenges of the embedding methods, but it also adds a layer of complexity.
The Training Phase: Learning the Translation Rules
When I begin the training phase, my focus is singular: to create a mapping function that is so robust it can generalize beyond the specific examples it sees. I’m not teaching the model what a cat is; I’m teaching it how to describe a cat in my system’s internal language.
This is a subtle but profound shift. The input data I work with consists entirely of seen categories, those for which I have both images and a deep, meaningful description. I gather thousands upon thousands of images for classes like “cat,” “dog,” and “horse.” But here’s the crucial part: I don’t just use a simple label.
Instead, for each class, I generate a semantic embedding, a dense vector of numbers that captures the rich meaning of that word.
I typically use a powerful language model like BERT for this, as it provides a vector that isn’t just a basic representation, but a contextualized one that understands the relationship of “cat” to “mammal,” “pet,” “feline,” and all other concepts it has been trained on. This gives my model a vocabulary of concepts that is rich and nuanced from the very start.
With my data in hand, I then proceed to the next step: feature extraction. I’ve learned from experience that trying to train a model on raw pixel data is a losing battle.
The noise is too high, and the patterns are too low-level. So, I always begin by passing the raw images through a pre-trained feature extractor, most often a powerful convolutional neural network (CNN) like ResNet or VGG.
These networks, having been trained on massive datasets like ImageNet, have already learned to identify the most fundamental visual patterns i.e., edges, textures, shapes, and other complex visual signatures.
The output of this CNN is a condensed numerical representation of the image’s visual features, a much richer and more informative input than pixels alone. This pre-processing step is non-negotiable for me, as it provides my zero-shot learning model with a “visual vocabulary” that is ready for translation.
The core of my work in this phase revolves around the learning process of the mapping function itself. The mapping function is a neural network I’ve designed to take the visual feature vector from my CNN and transform it into a new vector that lives inside my semantic space.
It’s learning the rules for translating from one representation to another. To train this network, I don’t use a simple categorical cross-entropy loss that just punishes for getting a label wrong. That would defeat the entire purpose.
Instead, I rely on more sophisticated loss functions, specifically a ranking loss or triplet loss. These functions are designed to teach relationships, not just classifications. For every training sample, I provide the model with a “positive” pair—the visual features of a cat and the semantic embedding for “cat”—and a “negative” pair—the visual features of a cat and the semantic embedding for an incorrect concept, like “car.” The loss function’s job is to ensure that the distance between the positive pair in the semantic space is always smaller than the distance between the negative pair. By doing this millions of times, I effectively force the network to learn a generalized, robust translation rule.
My ultimate goal in this phase is to make the mapping function so good at its job that if I give it the visual features of any “seen” class, its output in the semantic space will land precisely in the neighborhood of that class’s semantic embedding.
I’m building a translator that doesn’t just know a few phrases but understands the entire grammar of the visual-to-semantic language. The power of this approach is that the network learns to identify the shared visual patterns across different animals, or different objects, and map them to their respective conceptual meanings.
The Inference Phase: Applying the Translation to the Unseen
The moment of truth for me is always when I move to the inference phase. I’ve spent all this time training my mapping function on known categories, and now I get to see if it can perform a task that a conventional model simply cannot.
I present the trained AI with a new, unseen input—an image of a zebra. I know with absolute certainty that this model has never seen a single picture of a zebra during its training. The class label “zebra” was only ever present as a semantic embedding.
The process begins just as it did in training. The new image of the zebra is fed through my same pre-trained feature extractor, which converts the raw pixels into a visual feature vector. This vector, a numerical summary of the zebra’s visual characteristics, is then given to the mapping function.
I’ve spent months perfecting this function, and now it has to apply its learned rules to a completely foreign input. The function takes these new, unseen visual features and projects them into the same semantic space that it learned during training.
This is where my training strategy pays off. I watch as the projected point lands in a region of the semantic space that is close to where I know the semantic embedding for “horse” resides, but also near concepts like “stripes,” “black-and-white,” and “animal.” The model has created a conceptual representation of the unseen zebra based on its known visual and semantic building blocks. It’s a remarkable moment of pure reasoning.
The final step is for me to find the closest meaning. My system now has a new point in the semantic space, a representation of the visual features of the zebra. I then perform a nearest-neighbor search, calculating the distance between this new point and the semantic embeddings of all the classes in my knowledge base.
This includes not just the seen classes like “cat” and “horse,” but all the unseen ones as well, like “zebra,” “giraffe,” and “panda.” I use a distance metric like cosine similarity to determine which semantic embedding is most aligned with the newly projected visual vector.
The semantic description with the highest similarity score becomes my final prediction. Since the mapping function was designed to correctly learn the relationship between “striped, horse-like mammal” visuals and the “zebra” semantic description, my model correctly identifies the zebra. It’s an elegant, tangible example of the power of zero-shot learning—identifying an object without ever having seen an example of it.

Variants
Once you grasp the core concepts, you discover there are several variants of ZSL, each designed to tackle a different kind of real-world problem.
Generalized ZSL
This is the most realistic and challenging scenario. In the real world, a model won’t know if the object it’s looking at is a seen or an unseen class. My models needed to handle both. This is known as Generalized ZSL. It’s a tough challenge because the model often gets biased towards predicting the seen classes, as it has been trained on them extensively. The goal in GZSL is to maintain a high accuracy for both seen and unseen classes simultaneously.
Transductive ZSL
This variant is what happens when you have a bit of a sneak peek. In transductive ZSL, the model is given access to the unlabeled image data of the unseen classes during training. It doesn’t know what they are, but it can use their visual features to better structure the embedding space, making it easier to correctly classify them later. It’s a powerful approach when you have this kind of data available.
Evaluation & Metrics
When I started running experiments, I realized that getting a single “accuracy” number wasn’t enough. Evaluating ZSL required a specific set of metrics to truly understand my model’s performance:
- Top-1 Accuracy: The most common metric, measuring how often the model’s top prediction is correct.
- Top-K Accuracy: Similar to Top-1, but checks if the correct label is within the top K predictions. This is useful for seeing if the model is at least “in the right ballpark.”
- Harmonic Mean: For Generalized ZSL, this metric is a lifesaver. It combines the accuracy on seen and unseen classes into a single score, penalizing models that are heavily biased towards one set of classes.
Challenges & Limitations
My journey in zero-shot learning has taught me that the real world is never as simple as the theory.
While the two-phase approach provides an elegant solution, implementing it at scale brings with it some significant challenges that I’ve had to navigate. One of the most persistent problems I’ve encountered is what’s known as the hubness problem.
In high-dimensional spaces like the ones I work in, it’s a well-documented phenomenon that a few data points, or “hubs,” tend to become the nearest neighbors to a disproportionately large number of other points.
In my early models, this meant that the semantic embedding for a very common concept, like “mammal” or “animal,” would become the default prediction for almost every unseen image, even if the image was a car or a boat. The model was taking the path of least resistance.
To combat this, I had to implement more sophisticated techniques, such as dimensionality reduction, or using more complex normalization methods during the training process to prevent these hubs from forming in the first place.
I also began experimenting with alternative distance metrics beyond simple cosine similarity to mitigate this biasing effect. Another critical issue I’ve grappled with is the semantic gap problem. This is the fundamental disconnect between a computer’s low-level understanding of an image (pixels, edges, shapes) and a human’s high-level, conceptual understanding (language).
The visual feature extractor might capture an image of a new bird perfectly, but if it fails to extract a crucial feature like a specific crest or a unique wing pattern that is essential to the human description, then my mapping function will never be able to make an accurate projection.
It’s a failure of communication between the visual and semantic worlds. I’ve found that the best way to address this is by using more sophisticated generative models. By forcing the model to not just project an image to a semantic embedding, but to also generate a plausible visual representation from a semantic embedding, I can effectively bridge this gap.
This forces the model to learn a much more robust and aligned understanding between the two modalities. Finally, and perhaps most importantly for real-world applications, is the challenge of generalized zero-shot learning (GZSL). The ideal scenario is a closed-world setting where the model only ever sees unseen classes at inference time. The real world, however, is a blend of both.
A user might give my system an image of a new animal and an image of a horse, and my system has to correctly identify both. The major problem here is bias.
Since I’ve trained my model extensively on the seen classes, it develops a strong natural preference to predict them. This means that a new, unseen class is often misclassified as a known class. I’ve spent a lot of time on this, exploring a variety of solutions.
One approach I’ve found effective is to use a calibrated classifier that can determine the model’s confidence. If the confidence is high, it’s likely a seen class. If it’s low, the model should defer to its zero-shot reasoning. I’ve also experimented with more nuanced loss functions that specifically penalize this bias towards seen classes, pushing the model to be more open to novel predictions.
In my experience, zero-shot learning is a rewarding but challenging field. It’s not just about building a single neural network but about architecting a system that can learn from analogy and apply that knowledge to the great unknown.
I’ve found that by focusing on building a robust semantic space and a powerful mapping function, and by constantly grappling with the real-world challenges like hubness and the semantic gap, I can create systems that truly begin to exhibit a form of machine reasoning that goes beyond mere pattern recognition. This is what makes it so exciting for me.
The Advantages of Zero-Shot Learning Why It Matters So Much
After learning how it works, I became convinced that Zero-Shot Learning isn’t just a clever trick. It’s a paradigm shift that solves some of the biggest problems in AI today.
- Tackling Data Scarcity Head-On: I’ve spent countless hours collecting and labeling data for projects, and I can tell you it’s incredibly expensive and time-consuming. For rare or emerging categories, it’s often impossible. ZSL drastically reduces this burden. We only need labeled data for some categories, plus the semantic descriptions for the rest. This makes it invaluable in situations where data is inherently limited or difficult to obtain.
- Rapid Adaptability to the Unknown: Imagine you’re building a cybersecurity system that needs to identify new types of digital threats daily. Or a medical AI tasked with spotting symptoms of a newly emerging disease. You simply can’t train for every future possibility. ZSL allows these systems to recognize and react to anomalies or new concepts based on a generalized understanding, enabling rapid deployment and adaptation without needing extensive retraining.
- Enhanced Generalization: ZSL models are built to generalize. A model trained on a broad range of concepts can potentially apply its learned semantic understanding to entirely new domains or specific niches, simply by having descriptions of the novel categories. This is a powerful form of transfer learning.
- Cost-Effectiveness: By minimizing the need for constant, large-scale data collection and retraining for every new class, ZSL contributes to more efficient and cost-effective AI development and deployment.
These benefits highlight why ZSL isn’t just a theoretical curiosity. It’s a practical necessity for building truly robust and flexible AI systems in our dynamic world.
Real World Use cases Of Zero Shot Learning
When I first learned about ZSL, I thought it was just for image classification. But as I’ve continued my research, I’ve seen it applied in so many different ways that it’s reshaping how intelligent systems operate across diverse applications.
Zero-Shot Learning in Natural Language Processing (NLP)
The world of NLP has truly exploded, and a lot of that is thanks to the incredible power of massive language models. When you hear about LLM zero-shot learning, GPT zero-shot learning, or BERT zero-shot learning, you’re witnessing their astonishing ability to perform tasks they’ve never been explicitly trained on, simply by understanding your instructions.
For example, I’ve experimented with giving a large language model a news article and asking it to summarize it. It will do a great job without ever seeing a dedicated “summarization dataset” during its initial pre-training. This phenomenal capability stems from these models learning an immense amount of world knowledge and linguistic patterns. This deep understanding allows them to generalize to completely new tasks based on textual instructions alone.
I’ve seen how this is being applied in the real world. Models can classify customer feedback into unseen sentiment categories, identify new types of spam, or extract novel entities from text based purely on textual descriptions. It’s also being used in cross-modal applications.
For example, a frozen language model can provide rich textual embeddings for medical conditions, which can then be linked to ECG patterns, enabling the identification of heart conditions even if the system hasn’t seen labeled ECGs for every specific type.
To learn more about ZSL in NLP read my guide on My 3 Secrets to Master ZSL in NLP:
Zero-Shot Learning in Computer Vision
Zero-shot learning in computer vision has made colossal strides. I remember being blown away by an image classification system that could sort images into categories it’s never been trained on, simply because you gave it a text description of that category. This is what zero-shot learning image classification aims to achieve.
The emergence of powerful vision-language models (VLMs) has truly revolutionized this space. Models like OpenAI’s CLIP, which I’ve spent a lot of time with, are trained on massive datasets of images paired with their textual descriptions. This allows them to learn deep, multimodal connections between visual content and language. This is so powerful that they can understand concepts described in text and apply that understanding directly to unseen images.
This cross-modal understanding is so profound that vision-language models are being used as zero-shot reward models for reinforcement learning. An AI agent learning to navigate a complex environment can be guided by a VLM that provides “rewards” based on textual descriptions of desired outcomes, like “reach the red door,” rather than requiring painstakingly hand-coded reward functions for every scenario. This unlocks new levels of flexibility in training AI agents.
Furthermore, the development of large multilingual models has enabled zero-shot multimodal learning across languages. This means a VLM trained primarily on English image-text data can suddenly apply its visual understanding to classify images described in, say, Japanese or German, without the need for specific image-text pairs for those non-English languages. It’s a testament to the universal semantic space these models create.
Beyond Classification Other Zero-Shot Applications
The versatility of ZSL extends far beyond basic classification, which is something I find truly exciting.
- Zero-Shot Super-Resolution: Imagine improving the resolution of an image without needing a huge dataset of high-resolution and low-resolution pairs for that specific type of image. Techniques like zero-shot super resolution using deep internal learning uses patterns within a single image itself to enhance its quality, making it incredibly useful for old photographs or specialized imagery where training data is scarce.
- Zero-Shot Face Anti-Spoofing: Detecting fake faces, like photos or videos presented to a facial recognition system, is critical. Deep tree learning for zero-shot face anti-spoofing allows systems to identify new, unseen types of spoofing attacks by understanding the underlying characteristics of “real” versus “fake” faces, even if a specific attack method wasn’t in the training set.
- Multi-Label Zero-Shot Learning with Structured Knowledge Graphs: This advanced technique allows an AI to predict multiple attributes or labels for an unseen object by leveraging rich, interconnected knowledge graphs. Instead of just “cat,” it might predict “feline,” “domestic,” and “predator” for a new animal, even if it hasn’t seen examples with those specific multi-labels.
- Open-Domain Image Geolocalization: Can an AI tell you where an image was taken based solely on its visual features, even if it hasn’t seen images from that exact location before? Learning generalized zero-shot learners for open-domain image geolocalization explores this, using broader contextual cues and semantic understanding to pinpoint locations.
Zero-Shot Learning’s Relatives Understanding the Nuances
As you get deeper into AI, you’ll encounter terms that sound similar to ZSL but have crucial distinctions. When I was starting out, I found this part a little confusing, so I want to clarify it for you. We’ll look at the difference between few-shot learning vs. zero-shot learning and how they both relate to transfer learning.
Few-Shot Learning vs. Zero-Shot Learning A Matter of Examples
The primary difference between few-shot learning and zero-shot learning lies in the availability of examples for new categories:
- Zero-Shot Learning (ZSL): As we’ve discussed, ZSL requires zero labeled examples for the unseen categories. It relies purely on semantic descriptions and its ability to generalize from previously seen classes.
- Few-Shot Learning (FSL): FSL is slightly less ambitious, but still incredibly powerful. It requires a very small number of labeled examples, typically just 1 to 5, for a new category to learn to classify it. It’s like giving the AI a quick “crash course” on the new concept before it has to perform.
Both ZSL and FSL are vital for scenarios with data scarcity, but ZSL pushes the boundary further by needing literally no examples.
| Aspect | Zero-Shot Learning (ZSL) | Few-Shot Learning (FSL) |
| Examples of New Classes | Zero (0) examples. | Few (1 to 10+) examples. |
| Core Mechanism | Relies on semantic descriptions and a mapping function to infer knowledge from seen to unseen classes. | Relies on meta-learning or rapid adaptation from a few examples. |
| Level of Generalization | Extreme generalization. | Strong generalization, but with a small “nudge” from actual examples. |
| Data Requirement | Only requires semantic descriptions for new classes. | Requires a handful of labeled examples for each new class. |
| Typical Scenario | Identifying completely novel objects or concepts. | Rapid adaptation to new, related tasks. |
| Robustness | Can be more sensitive to the quality of semantic descriptions. | Generally more robust and achieves higher accuracy than ZSL. |
For a more detailed comparison, you can read this guide.
Zero-Shot Learning vs. Transfer Learning
You might also wonder about zero-shot learning vs. transfer learning. This is a great question. While ZSL is often considered a specialized form of transfer learning, there’s a key distinction:
- Transfer Learning (Traditional): In a typical scenario, you take a model that’s already an expert at one task, say image classification, and then you fine-tune it on a smaller, labeled dataset for your specific target task, like classifying a specific type of plant. The model transfers its learned features to a new but related domain.
- Zero-Shot Learning (ZSL): ZSL, as we know, requires no labeled data for the target categories. It relies on a more abstract form of knowledge transfer, the semantic understanding, to directly classify unseen classes.
So, while both are about leveraging pre-existing knowledge, ZSL is the extreme case of transfer learning where no direct target-specific examples are needed.
The Cutting Edge and My Journey Forward
The field of Zero-Shot Learning is incredibly dynamic. It feels like every week I’m reading a new paper or seeing a new technique that pushes the boundaries of what’s possible.
One of the most realistic and challenging scenarios I’ve been following is Generalized Zero-Shot Learning (GZSL). Unlike traditional ZSL, where the model only encounters unseen classes during testing, a GZSL model must be able to classify inputs that could belong to either seen or unseen classes. This introduces a bias problem, as models tend to favor the seen classes they were trained on. Addressing this bias and ensuring fair classification is a major research focus. Techniques like learning generalized zero-shot learners for open-domain image geolocalization are examples of GZSL pushing boundaries in complex tasks.
Other innovative approaches that have caught my eye include:
- Generative Approaches: I’ve been fascinated by methods that use Generative Adversarial Networks (GANs) to synthesize features for unseen classes from their textual descriptions. This effectively “creates” synthetic training data for the unseen categories, turning ZSL into a supervised problem. This is especially useful when dealing with ambiguous or noisy texts.
- Bayesian Zero-Shot Learning: This approach incorporates probabilistic reasoning and uncertainty into the ZSL framework, often leading to more robust predictions and better handling of ambiguity.
- Context-Aware Zero-Shot Learning: This is a very cool idea in computer vision. It considers the surrounding environment or other objects in an image when classifying an unseen object, leveraging the natural co-occurrence of objects to improve accuracy.
Practical Zero-Shot Learning Getting Your Hands Dirty
After all this theory, you might be wondering, “How do I actually get started?” The good news is, accessing and implementing zero-shot learning models has become increasingly accessible.
Python is the go-to language for AI development, and you’ll find implementations in popular deep learning frameworks like TensorFlow and PyTorch. If you’re a developer like me, you’ll be excited to know that the Hugging Face Transformers library has become an absolute cornerstone for NLP. It offers powerful pre-trained models that can be used for a wide range of zero-shot tasks, and it makes getting started a breeze.
If you want to learn python you can access my free python tutorials here.
My Final Thoughts A Journey to the Future
Looking back at my own journey with AI, discovering Zero-Shot Learning has been one of the most exciting experiences. It taught me that the future of AI isn’t just about bigger models and more data. It’s about building smarter, more efficient, and more human-like systems that can learn and reason about the world in a way that is far more flexible and intuitive.
Zero-Shot Learning isn’t just a theoretical concept. It’s a paradigm shift that fundamentally changes how we think about AI and data. It represents a significant step towards creating more intelligent, autonomous, and adaptable systems. I hope this guide has inspired you to explore this amazing field, just as I was inspired to write about it.
Happy learning!

Stay ahead of the curve with the latest insights, tips, and trends in AI, technology, and innovation.