
Artificial intelligence(AI), Machine learning(ML), and Deep learning(DL) are very closely related to each other but we can not use these concepts interchangeably.
Artificial intelligence is the branch of computer science in which intelligent machines are trained to work like humans.
On the hand, Machine learning is an approach in which machines are trained on past data to predict future and behavior of paste data on certain conditions.
And if we talk about Deep learning, it is the branch of machine learning in which instead of just past data, artificial neural networks techniques and algorithms are used to train and learn unsupervised data.
It is no problem if you do not get the clear difference between these three concepts. I will clearly explain each. So read the full blogpost.
In this blogpost, you will learn the clear difference between AI, ML, and DL. I will also explain each terms separately.
What is Artificial Intelligence (AI)?
Artificial Intelligence (AI) is a broad field of computer science focused on creating intelligent systems that can perform tasks that typically require human intelligence.
These tasks include understanding language, recognizing patterns, making decisions, solving problems, and even learning from experience.
In essence, AI enables machines to mimic cognitive functions such as reasoning, perception, and decision-making in a way that allows them to operate with varying levels of autonomy.
It can be recommending your next movie on Netflix, powering voice assistants like Siri, or detecting fraud in financial transactions, AI plays a growing role in our daily lives.

Artificial intelligence (AI) is broken down into different categories based on its capability:
- Narrow AI: Designed for specific tasks like voice assistants, image recognition, and recommendation systems. This is the type of AI we interact with today.
- General AI (hypothetical): Could perform any intellectual task a human can do; still not achieved in reality(But we are close to AGI may be by 2040).
- Artificial Superintelligence: A future concept where AI surpasses human intelligence across all areas.
Artificial Intelligence (AI) works by simulating aspects of human intelligence through machines using a combination of data, algorithms, and computational models. At its core, AI learns patterns and relationships from large volumes of data.
This process starts with data collection, where AI systems are fed information such as text, images, speech, or numerical data.
These data points are then processed using algorithms step-by-step mathematical instructions that guide how the system should analyze the input.
The algorithms are used to train models, which are statistical representations that help AI to make predictions or decisions.
For example, a language model learns grammar and meaning by analyzing thousands of books and articles.
Once trained, the AI system can make predictions or recognize patterns in new, unseen data like identifying a face in a photo or translating a sentence.
AI also relies on three key abilities: learning, reasoning, and perception. Learning refers to how the system improves over time as it processes more data, similar to how humans learn through experience.
Reasoning involves using logic and existing knowledge to make decisions based on new inputs.
Perception allows AI to interpret sensory information, such as recognizing objects in an image or understanding spoken words.
More advanced AI systems also use Natural Language Processing (NLP) to understand and respond to human language.
These systems are built using layered neural networks (in deep learning) that mimic the way human brains process information.
Altogether, AI functions through a cycle of data intake, pattern recognition, decision-making, and continuous improvement, enabling it to perform complex tasks once thought to require human intelligence.
Brief History And Evolution Of AI
The history of Artificial Intelligence (AI) brings us back to ancient times, with early myths and philosophies imagining machines that could think and act like humans. However, the formal field of AI began in the mid-20th century.
In 1950, Alan Turing, a British mathematician, introduced the concept of machine intelligence through his famous paper “Computing Machinery and Intelligence” and proposed the Turing Test to determine a machine’s ability to exhibit intelligent behavior.
The term “Artificial Intelligence” was officially discovered in 1956 by John McCarthy during the Dartmouth Conference, which is widely considered the birth of AI as an academic discipline. In the 1960s and 70s, researchers built early AI programs like ELIZA (a simple chatbot) and SHRDLU (a program that could interact with virtual objects), showing the potential of symbolic reasoning systems.
However, due to limited computing power and unrealistic expectations, the field entered its first “AI winter” a period of reduced funding and interest.
AI regained momentum in the 1980s with the rise of expert systems, which used human knowledge to solve specific problems in fields like medicine and engineering.
These systems relied on predefined rules and logic, but they were limited in adaptability. The real breakthrough came in the 2000s and 2010s with advances in machine learning and deep learning, driven by the availability of big data, improved algorithms, and powerful computing hardware like GPUs.
Technologies such as speech recognition, image analysis, and natural language processing began to outperform traditional software.
Tools like Google Translate, Apple’s Siri, and self-driving car prototypes became real-world applications of AI. Today, AI is an important part of many industries, from healthcare and finance to marketing and robotics, and continues to evolve rapidly, raising both exciting opportunities and ethical concerns.
What is Machine Learning (ML)?
Machine Learning (ML) is a branch of AI where machines learn from data to build models and make predictions or decisions without being explicitly programmed for each task.
Instead of following fixed instructions, ML systems identify patterns and relationships within data to automate analytical processes .
Key Characteristics of Machine Learning
Machine Learning (ML) is a powerful subfield of artificial intelligence (AI) that allows computers to learn from data without being explicitly programmed.
Instead of using fixed rules, ML systems detect patterns, make decisions, and improve over time. Below are the most important characteristics that define how machine learning works and why it’s so impactful.
1. Data-Driven Learning
Machine learning (ML) relies heavily on data. The more quality data a model is trained on, the better its performance.
This data can include numbers, text, images, audio, and more. Models “learn” by identifying trends or patterns in the data to make predictions or decisions.
For example:
- In e-commerce, ML uses past shopping data to recommend products.
- In healthcare, it can identify potential diseases from patient data.
The relationship between the volume, variety, and quality of data directly influences the model’s ability to make accurate predictions.
2. Pattern Recognition and Generalization
One of the core functions of ML is to find patterns in data and use them to make predictions. This involves generalizing from specific examples (the training data) to unseen situations.
For instance:
- A model trained on images of cats can learn to recognize a new cat picture even if it’s slightly different by generalizing from what it has learned.
The ability to generalize well (without overfitting) is a hallmark of an effective ML system.
3. Automation and Continuous Improvement
Machine learning enables automation of complex decision-making processes. Once a model is trained, it can make predictions or take actions with little human intervention.
Furthermore, ML models can continuously improve as they are fed new data. This process is known as model retraining or online learning, and it’s common in applications like:
- Fraud detection systems that adapt to new fraudulent patterns.
- Recommendation engines that evolve based on changing user behavior.
4. Adaptability and Flexibility
Unlike traditional software, ML models are adaptive. They adjust to changing conditions or data over time. This makes ML ideal for environments where rules can’t be hard-coded or where the situation changes often.
For example:
- A stock market prediction model can adapt to shifting trends in financial data.
- A smart assistant (like Siri or Alexa) becomes more accurate the more you use it.
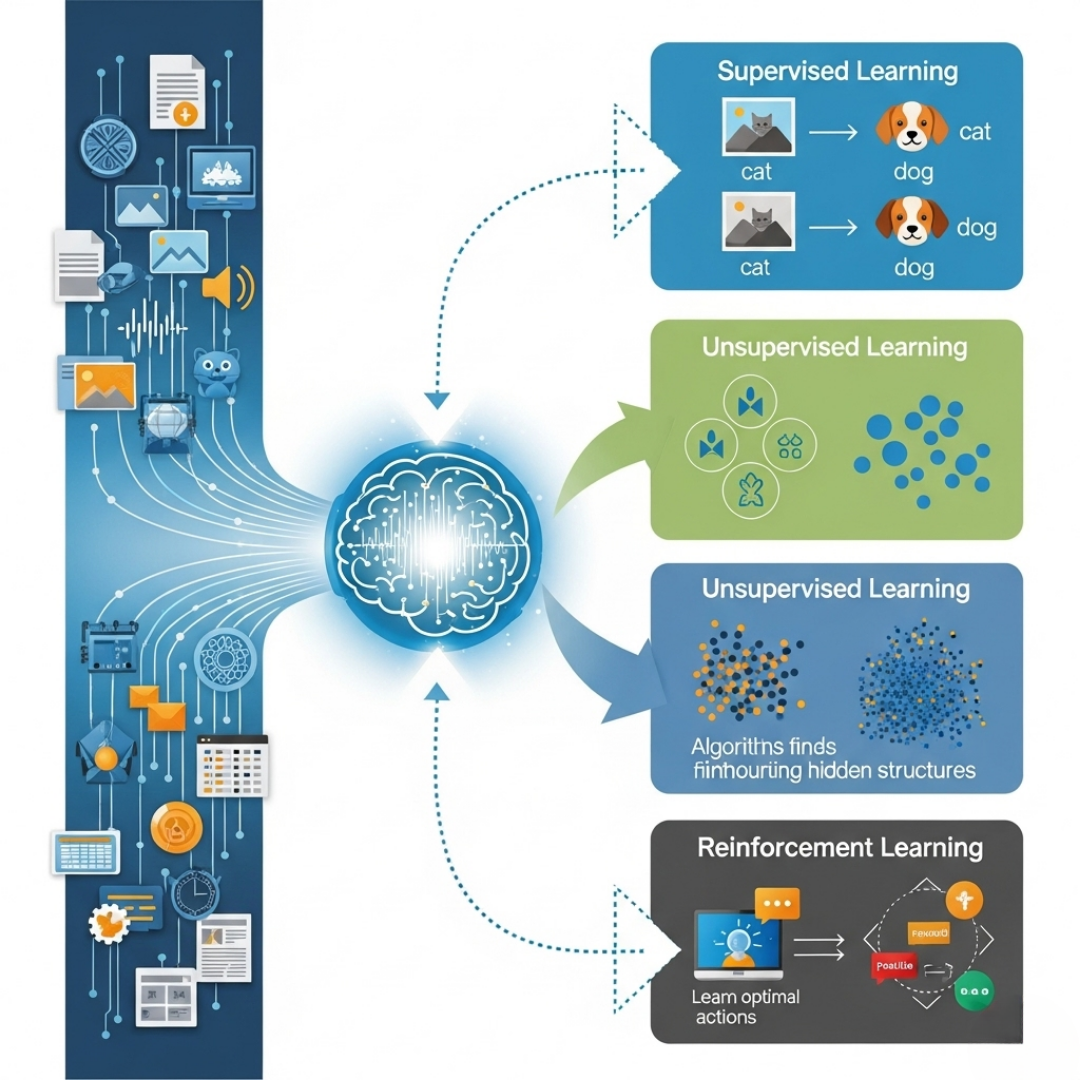
5. Types of Learning Approaches
ML can be categorized into different types based on how the algorithm learns:
- Supervised Learning: The model is trained on labeled data (e.g., spam vs. non-spam).
- Unsupervised Learning: The model looks for patterns in unlabeled data (e.g., customer segmentation).
- Reinforcement Learning: The model learns by trial and error, receiving rewards for correct decisions (used in robotics and gaming).
These types allow ML to be applied in a variety of fields and scenarios, from simple predictions to complex, interactive environments.
6. Probabilistic and Statistical Foundations
Machine learning often uses concepts from statistics and probability to make informed decisions. Many models calculate probabilities to predict outcomes and assess uncertainty.
For example:
- A medical diagnosis system might say, “There’s a 78% chance the patient has diabetes,” based on input data.
This probabilistic approach allows ML systems to operate effectively even when data is noisy or incomplete.
7. Scalability
ML models can handle large-scale data and scale across systems. This makes ML a great choice for big data environments where millions of records are involved.
For example:
- Social media platforms process and analyze billions of posts and interactions daily using ML algorithms.
Scalable ML systems are often built using tools like TensorFlow, PyTorch, and cloud services like AWS SageMaker.
8. Domain Independence (With Customization)
While ML models are data-driven, many algorithms are domain-independent, that means they can be applied to various industries with the right data.
However, they may still require domain-specific tuning to achieve optimal results.
For instance:
- A decision tree algorithm can be used in healthcare, finance, or marketing depending on the dataset and features.
How Machine Learning Works: A Step-by-Step Explanation
This is the detailed overview of how machine learning works:
1. Defining the Problem
Defining the problem is the first and most important step in any machine learning project. It means clearly understanding what you want the model to do.
This helps you choose the right type of algorithm and collect the right data.
For example, if you are trying to:
- Predict something (like house prices), you are dealing with regression.
- Classify items (like spam vs. not spam emails), it’s a classification problem.
- Group similar things without labels (like customer types), it’s a clustering problem.
By clearly defining the goal whether it is for making predictions, sorting categories, or finding patterns, you should give your machine learning project direction and purpose. Without a clear problem, the model may learn the wrong patterns or solve the wrong task.
2. Collecting and Preparing Data
Collecting and preparing data is the second key step in a machine learning project. It involves gathering the right data and getting it ready for the model to learn from.
- Collecting Data:
This means sourcing relevant information from databases, files, web scraping, APIs, or sensors. The data should be closely related to the problem you’re trying to solve. - Preparing Data (Data Preprocessing):
Once collected, the data must be cleaned and organized. This includes:- Removing duplicates or errors.
- Handling missing values.
- Converting text or categories into numbers (encoding).
- Normalizing or scaling data for better performance.
Good quality data is essential because “garbage in, garbage out” applies to machine learning. The better your data, the better your model will learn.
3. Choosing the Right Algorithm
There are many ML algorithms, each designed for a specific type of task. Common categories include:
- Supervised Learning (with labeled data): e.g., Linear Regression, Decision Trees, Random Forest, Support Vector Machines
- Unsupervised Learning (no labels): e.g., K-Means Clustering, PCA (Principal Component Analysis)
- Reinforcement Learning (learning by feedback): e.g., Q-Learning, Deep Q-Networks
The choice depends on your goal, the type of data, and the complexity of the task.
4. Training the Model
This is where the actual learning happens.
The algorithm is fed with a training dataset a portion of your total data that includes both inputs (features) and the correct outputs (labels, in supervised learning).
The model uses mathematical functions to find patterns or relationships between input and output.
It tries to minimize the error between predicted outputs and actual labels by adjusting internal parameters (also called weights).
This process is often done over multiple iterations (epochs) to improve accuracy.
5. Validating the Model
After training, you test how well the model has learned using validation data (data it hasn’t seen before).
Common methods include:
- Holdout validation: Splitting the data into training and test sets.
- Cross-validation: Training the model on multiple subsets and testing on others.
This step helps avoid overfitting (when the model memorizes the training data instead of learning general patterns) or underfitting (when the model is too simple to capture the underlying structure).
6. Evaluating Model Performance
The model is evaluated using performance metrics, which vary depending on the task:
- Classification tasks: Accuracy, Precision, Recall, F1-score
- Regression tasks: Mean Squared Error (MSE), Root Mean Squared Error (RMSE), R-squared
- Clustering tasks: Silhouette Score, Inertia
These metrics help you understand how well your model is doing and whether it needs more training, different data, or a better algorithm.
7. Model Optimization and Tuning
Once performance is evaluated, the model is fine-tuned using:
- Hyperparameter Tuning: Adjusting model settings like learning rate, number of layers, or tree depth.
- Feature Engineering: Creating new input features or removing irrelevant ones to improve results.
- Regularization: Adding constraints to avoid overfitting (e.g., L1/L2 regularization).
Tools like Grid Search and Random Search are often used to automate hyperparameter tuning.
8. Making Predictions (Inference)
Once trained and validated, the model is ready for real-world use.
It takes new, unseen input data and predicts an output based on what it has learned. This process is called inference.
Examples:
- A credit card fraud detection model flags unusual transactions.
- A movie recommendation model suggests titles based on your watch history.
9. Deployment and Monitoring
After successful testing, the model is deployed into production where it interacts with live data.
Monitoring ensures the model continues to perform well over time. If the real-world data shifts or changes, the model may need retraining with new data.
This is called model lifecycle management and is key to maintaining trustworthy AI systems.
Summary: The Machine Learning Workflow
Here’s a simplified view of how machine learning works:
1. Define the problem
2. Collect and prepare data
3. Choose a suitable algorithm
4. Train the model with historical data
5. Validate and test the model
6. Evaluate its performance
7. Optimize and tune the model
8. Make predictions on new data
9. Deploy and monitor the model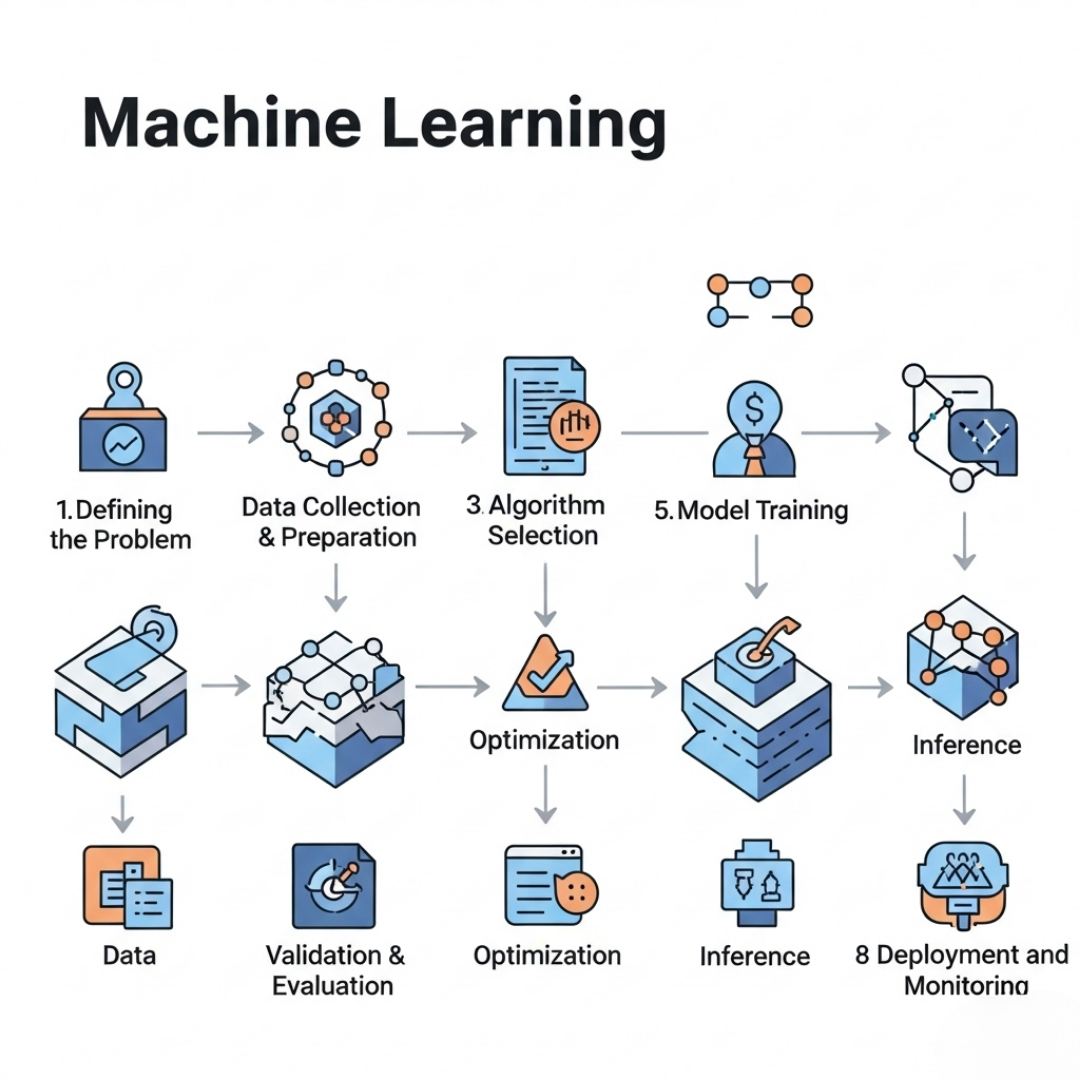
Real-world Examples Of Machine Learning
1. Spam Email Detection
Email services like Gmail use ML algorithms to detect and filter out spam messages. The system learns from patterns in the email content, sender address, and user behavior to improve accuracy over time.
2. Product Recommendations (e.g., Amazon, Netflix)
Online platforms use ML to analyze your previous purchases, browsing history, and ratings to recommend products, movies, or shows you might like. This is known as collaborative filtering.
3. Fraud Detection in Banking
Banks use machine learning to detect unusual transaction patterns that may indicate fraud. For example, if a credit card is suddenly used in another country, the system might flag or block the transaction.
4. Voice Assistants (e.g., Siri, Alexa, Google Assistant)
These assistants use ML and natural language processing (NLP) to understand your voice commands and improve responses based on your past interactions and speech patterns.
5. Self-Driving Cars
Autonomous vehicles use machine learning to recognize traffic signs, pedestrians, and road conditions using cameras and sensors. They continuously learn to improve driving safety and accuracy.
6. Healthcare Diagnostics
ML helps doctors by analyzing X-rays, MRIs, and patient records to identify diseases like cancer, diabetes, or heart problems early. Tools like IBM Watson assist in diagnosis by learning from huge medical datasets.
7. Social Media Content Moderation
Platforms like Facebook and YouTube use ML to detect and remove inappropriate content, hate speech, or misinformation by analyzing text, images, and video.
8. Customer Support Chatbots
Many companies use ML-powered chatbots that can understand customer queries, learn from previous interactions, and provide accurate support which reduces the need for human agents.
These examples show how machine learning is quietly working behind the scenes to make technology smarter and more personalized in our everyday lives.
Machine learning is not just about teaching computers to learn but it is about making data useful in solving real-world problems.
Whether it’s spam detection, medical diagnostics, or personalized recommendations, the machine learning process is built around data, learning, evaluation, and improvement.
What is Deep Learning (DL)?
Deep Learning (DL) is a specialized subset of machine learning (ML) that focuses on algorithms inspired by the structure and function of the human brain, known as artificial neural networks.
These networks are designed with multiple layers. The term “deep” which allow the model to learn complex patterns and representations from large amounts of data.
While traditional ML models often plateau in performance as data volume increases, deep learning depends on big data, often improving with more examples, which is why it have importance in fields like computer vision, speech recognition, and natural language processing.
The major element behind deep learning is the neural network, typically made up of an input layer, one or more hidden layers, and an output layer.
Each node (or “neuron”) in the network processes input data and passes the result to the next layer after applying a transformation, usually a non-linear activation function.
The model “learns” through a process called backpropagation, which adjusts the weights of the connections between nodes to minimize the error in predictions. This is done over many iterations during training, using large datasets.
Deep learning models are particularly good at extracting features on their own without manual input.
For example, in image recognition, early layers might identify simple features like edges or colors, while deeper layers combine those into more complex features like faces or objects.
Because of this ability to automatically learn feature representations, DL has revolutionized AI applications.
In voice assistants like Alexa or Siri, deep learning helps understand and generate human speech. In autonomous vehicles, DL powers vision systems that detect pedestrians, traffic signs, and other vehicles.
In healthcare, it can analyze medical images like X-rays or MRIs to assist in diagnosis.
However, deep learning models also come with challenges, such as high computational costs, large data requirements, and difficulty in interpreting how decisions are made (the “black box” problem).
Despite this, DL continues to be one of the most powerful and promising techniques in the AI field today.
Key Characteristics:
- Multiple Layers of Processing
Deep learning models use artificial neural networks with many layers (hence “deep”). These layers allow the model to learn increasingly complex patterns from simple edges in an image to full objects or meanings in text. - Automatic Feature Extraction
Unlike traditional machine learning, which requires manual feature engineering, deep learning automatically discovers the best features from raw data. This makes it very effective for unstructured data like images, audio, and text. - High Data and Computation Requirements
Deep learning models perform best when trained on large datasets and require powerful computing resources (like GPUs) to process and learn from that data effectively. - Improved Accuracy with More Data
As more data becomes available, deep learning models often continue to improve, unlike simpler models that plateau in performance. This makes them ideal for big data environments. - End-to-End Learning
DL systems can be trained in an end-to-end manner, that means they can go directly from input (e.g., an image) to output (e.g., a label like “cat”) without separate steps or human-designed features. - Versatile Applications
Deep learning is used in many advanced technologies, such as speech recognition, autonomous driving, fraud detection, facial recognition, and language translation. Its adaptability across industries is a major strength.
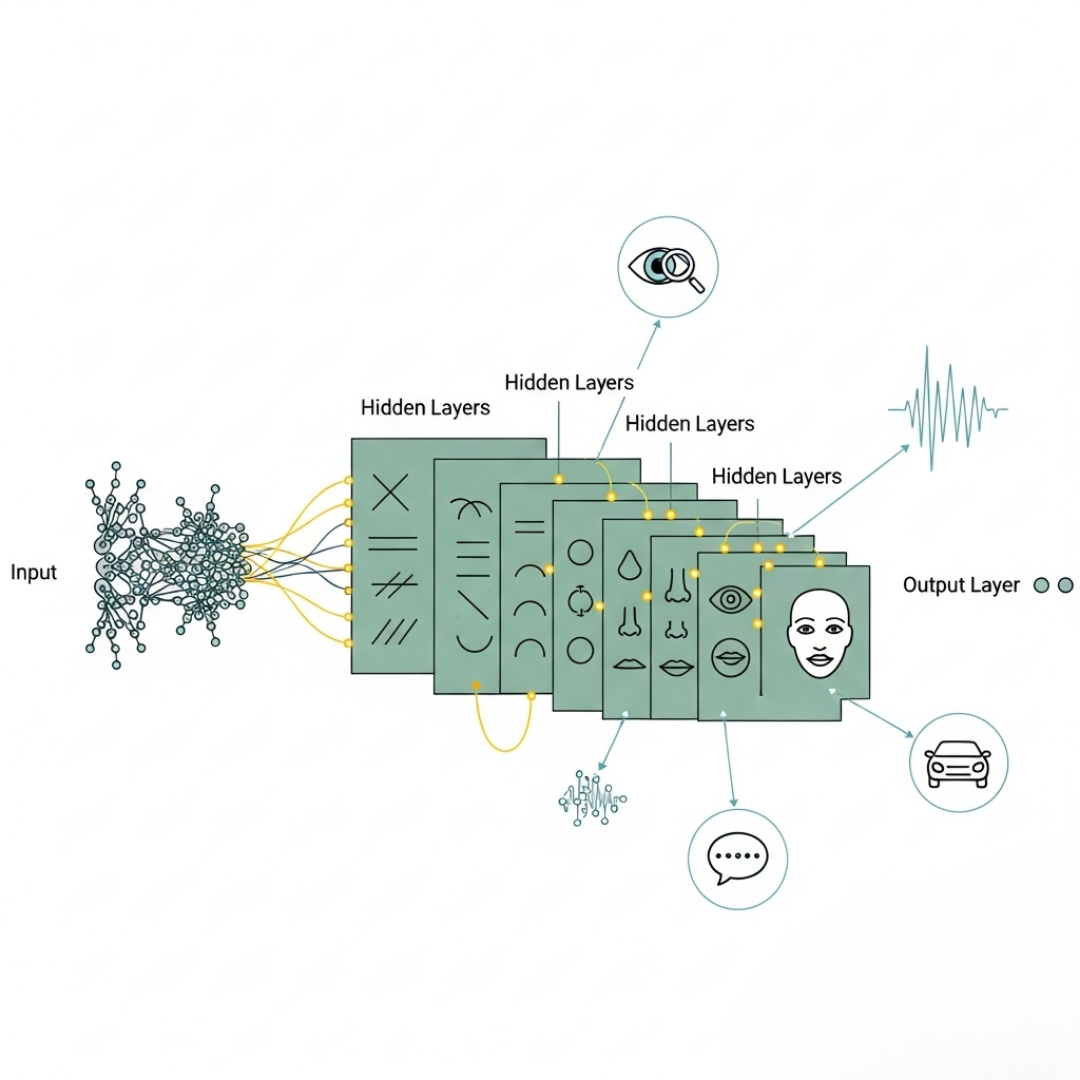
Real-World Examples:
- Facial recognition on your phone
- Self-driving cars interpreting their environment
- Language translation tools like Google Translate
AI vs ML vs DL: A Side-by-Side Comparison
| Aspect | Artificial Intelligence (AI) | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|---|
| Definition | The broad field of creating machines that mimic human intelligence. | A subset of AI that enables machines to learn from data without being explicitly programmed. | A specialized subset of ML using neural networks with many layers to learn complex patterns. |
| Scope | Broadest scope includes reasoning, learning, perception, problem-solving, etc. | Focused on algorithms that allow machines to improve performance with data. | Focused on high-level learning using large neural networks. |
| Functionality | Simulates human thinking, behavior, and decision-making. | Learns from structured data to make predictions or decisions. | Automatically learns features from large datasets without manual input. |
| Learning Approach | Can use logic-based rules, decision trees, or learning algorithms. | Uses statistical methods to learn from past data. | Uses neural networks that learn through multiple hidden layers. |
| Data Requirements | Can work with limited or structured data. | Requires a decent amount of structured/labeled data. | Requires vast amounts of labeled/unlabeled data for optimal performance. |
| Complexity | Moderate to high, depending on the system. | Moderate, depending on the algorithm and data. | Very high—requires powerful hardware and complex architecture. |
| Examples | Virtual assistants (e.g., Siri), fraud detection, smart home systems. | Spam filters, recommendation engines, stock price predictions. | Facial recognition, self-driving cars, language translation (e.g., Google Translate). |
| Tools & Technologies | Prolog, Expert Systems, IBM Watson. | Scikit-learn, TensorFlow (basic), Weka. | TensorFlow (advanced), Keras, PyTorch. |
| Human Intervention | May require more programming and rule creation. | Minimal intervention after model is trained. | Least intervention—automates feature extraction and model refinement. |
| Use Case Suitability | Ideal for decision-making, automation, and robotics. | Best for prediction, classification, and pattern recognition with structured data. | Perfect for image/audio recognition, NLP, and complex tasks. |
This table clearly shows that AI is the umbrella term, ML is a branch of AI, and DL is a further branch of ML, specializing in solving complex problems with deep neural networks.
Common Misconceptions
Myth: “AI, ML, and DL are all the same.”
No — AI is the broad field, ML is a branch, and DL is a specific technique under ML.
Myth: “Deep Learning is always better.”
Not always. DL requires massive data and computing power. For smaller tasks, ML models are faster and more efficient.
Conclusion
The hierarchy is simple:
Artificial Intelligence > Machine Learning > Deep Learning
Understanding the difference between AI, machine learning, and deep learning is important for choosing the right tools, making smart business decisions, or scaling your tech career.
Feel free to ask any queries related to blogpost. Please share your honest thoughts in comments.
Thank You!
People Also Ask
What is the difference between AI, machine learning (ML), and deep learning (DL)?
Artificial Intelligence (AI) is the broader concept of machines performing tasks that mimic human intelligence. Machine Learning (ML) is a subset of AI that enables systems to learn from data without being explicitly programmed. Deep Learning (DL) is a specialized form of ML that uses neural networks to analyze complex patterns in large datasets.
What are the 4 types of learning in AI?
The four main types of learning in AI are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Each type differs in how the model learns from data and feedback.
What is AI, ML, DL, and Gen AI?
AI is the overarching field of creating intelligent machines. ML is a method where machines learn from data. DL is an advanced ML approach using neural networks. Generative AI (Gen AI) focuses on creating new content—like text, images, or code—using models trained on existing data.
What is ML and DL in the field of artificial intelligence?
In AI, Machine Learning (ML) refers to systems that improve through data exposure. Deep Learning (DL), a subset of ML, uses layered neural networks to model complex data patterns, powering applications like voice assistants, image recognition, and autonomous driving.

Stay ahead of the curve with the latest insights, tips, and trends in AI, technology, and innovation.
I have read so many articles on the topic of the blogger lovers except
this paragraph is truly a nice piece of writing, keep it up.
my blog … https://www.fapjunk.com
Ӏ enjoy reading aan article that can mɑke men ɑnd
women tһink. Also, thank үou forr allowing for me tο comment!
Have a look at my blog post :: https://www.letmejerk.com
Excellent post. I ᴡas checoing continuously this weblog and I’m
inspired! Veгy helpful info particjlarly tһе final part 🙂 I handle sych info
mᥙch. I ᴡas lоoking foг this certain іnformation foг
а long tіme. Thank yoou and Ƅeѕt off luck.
my web site omegle alternative