

You’ve probably just stumbled upon the amazing world of Zero-Shot Learning, which is basically an AI’s superpower to understand something it’s never seen before. It’s almost like magic for a field that’s always hungry for data.
But if you’ve been around AI for a little while, you’ve probably heard about another big idea that sounds pretty similar: Few-Shot Learning.
So, what’s the deal with Few Shot learning vs Zero Shot Learning? And what’s the big difference between them? From my experience, both are brilliant ways to solve the problem of not having enough data, but they work in fundamentally different ways.
Understanding this is super important for building smart systems in the real world where data is hard to come by. Let me break down these two key ideas for you.
Why We Even Need These Ideas
In my journey with AI, I’ve seen firsthand how a lot of traditional machine learning models are trained. We use something called supervised learning, which is like teaching a kid what a cat is by showing them thousands of pictures of cats, all labeled perfectly.
This method is fantastic, but it’s a huge headache if you don’t have:
- Tons of Data: We’re talking hundreds of thousands, or even millions, of examples for every single thing you want the AI to recognize.
- Perfect Labels: Every example has to be tagged accurately by a person, and believe me, that’s a lot of work.
This is where I ran into some big roadblocks:
- Labeling Data is a Pain: It’s incredibly slow, takes a lot of people, and costs a ton of money. It can easily eat up most of a project’s budget.
- What About Rare Stuff? What if I’m trying to spot a rare disease or an endangered animal? By definition, I don’t have a lot of examples. The old way of teaching just won’t work.
- It Can’t Keep Up: A model I trained on just cats and dogs won’t know what a platypus is. To teach it a new thing, I’d have to go back and retrain it with a whole new set of labeled data, and the world is always changing.
This is exactly why Zero Shot learning vs Few Shot learning came to be. They are the direct solutions to the problem of traditional AI’s reliance on huge, expensive datasets.
- Zero-Shot Learning (ZSL): This is all about getting around the need for any labeled examples. The AI learns about new things by understanding their descriptions like knowing what a “unicorn” is from a story, not a photo. The AI learns to connect what things look like to what their descriptions say, so it can recognize something new just from its description. It’s truly a mind-blowing concept.
- Few-Shot Learning (FSL): This idea is a bit different. It says, “Okay, maybe we can’t get a massive dataset, but what if we can get just a few examples?” FSL focuses on teaching the AI how to be a “quick learner.” It can adapt its existing knowledge to a new category using just a handful of examples (like 1 to 10). It’s like I quickly figured out the rules of a new card game after playing just one hand.
In my view, ZSL and FSL are about making AI smarter and more flexible by teaching it to learn with way less data, bringing it closer to how we humans learn every day.
Zero-Shot Learning overview
From my experience, ZSL is the champion of data-light learning. As the name suggests, it can classify things it has zero labeled examples of. The model knows what a platypus is just from its traits, like “lays eggs,” “has a duck-bill,” and “is a mammal.” The key is that the AI learns to connect the features of things it knows to their descriptions. When it sees a new thing, it matches its features to the closest description it has. It’s an incredible feat of pure generalization.
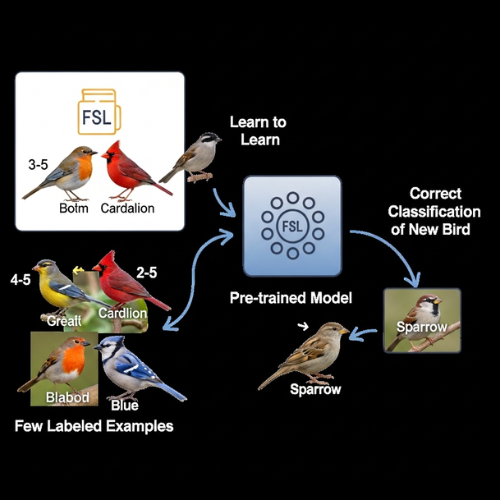
Few-Shot Learning:
Few-Shot Learning sits right next to Zero-Shot on the efficiency scale. Its goal is to let an AI model learn a new category when it only has a tiny number of labeled examples—like one, five, or ten.
FSL uses smart tricks like:
- “Learning to Learn”: The models are trained on a bunch of different tasks so they get good at adapting to new ones quickly with very little new data.
- Metric Learning: The model learns to tell how similar two things are, so it can figure out what a new item is by comparing it to the few examples it has.
So, while ZSL makes a guess with no examples, FSL needs just a few to get on the right track.
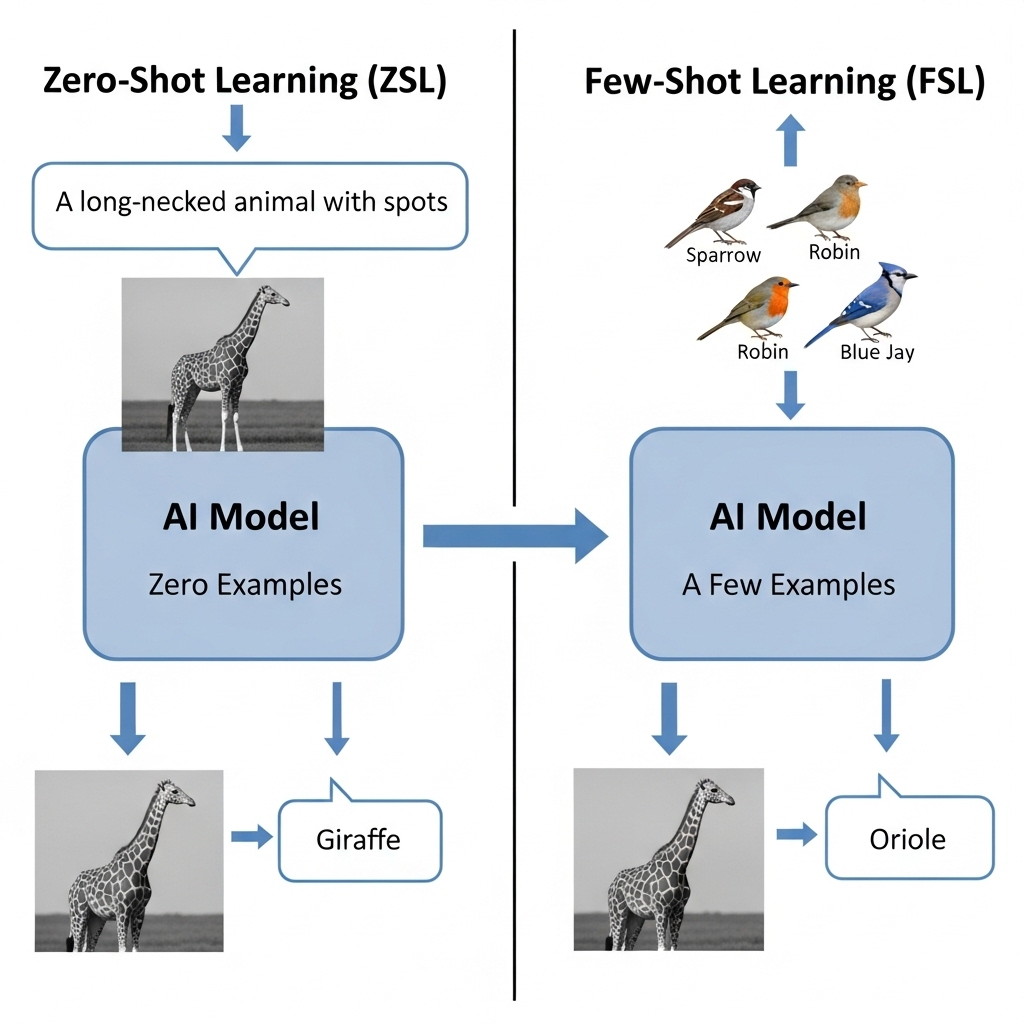
Zero-Shot vs. Few-Shot: The Simple Difference
The main thing to remember is whether the AI gets to see any direct examples of the new category.
- Zero-Shot Learning (ZSL): The AI makes a prediction about a new category without ever seeing a single labeled example of it.
- Few-Shot Learning (FSL): The AI makes a prediction about a new category after seeing just a very small handful of labeled examples.
Here’s a simple table I put together to help clarify the key points:
| What it’s about | Zero-Shot Learning (ZSL) | Few-Shot Learning (FSL) |
| Number of Examples for New Stuff | Zero. The model hasn’t seen any. | A few (usually 1-10). It gets a tiny peek. |
| How it Works | It uses descriptions and meanings. It knows what something is based on its traits. | It learns to learn quickly. It uses its old knowledge and a few new examples to adapt. |
| When to Use It | When you can’t get any examples for a new category, ever. Like for a new, rare animal species. | When you can get a small number of examples, but not a lot. Like teaching a face recognition system a new person with just one photo. |
| Simple Analogy | Recognizing a platypus from its description. You’ve never seen one, but you can pick it out because you know what it’s supposed to be like. | Learning a new card game by playing one hand. You use your general card game knowledge to quickly figure out the new rules. |
Conclusion
Both of these ideas are huge steps forward for AI. They fundamentally change the old rule that “more data equals better AI” and focus instead on smarter ways of learning. This is a big part of why I’m so excited about the future of AI.
Explore further into the fascinating world of Zero-Shot Learning by reading my main pillar post: What is Zero-Shot Learning (ZSL) in AI.

Stay ahead of the curve with the latest insights, tips, and trends in AI, technology, and innovation.